
The Community of Practice on AI systems as digital public goods, co-hosted by the DPGA and UNICEF, has developed and mapped a first approach to distinguish the degrees of openness of an AI system’s components. Doing so can help equip developers with a tool to think through how and when to open AI systems. This work forms the basis for formulating recommendations for the evolution of the DPG Standard and focuses on AI systems, including, but not limited to, generative AI.
UNICEF and the Digital Public Goods Alliance (DPGA) recognise the positive potential of AI, particularly in international development, and are committed to its responsible use in order to benefit society at large. For this reason, they joined forces in the spring of 2023 to convene a Community of Practice (CoP) which brings together experts from diverse sectors and geographies to explore AI systems as digital public goods: open, accessible, and adaptable tools that can be used to help achieve the sustainable development goals safely and inclusively.
In particular, this CoP aims to look at the intersection of responsible and open AI, understanding that while openness in AI has many benefits, including increased transparency, external oversight, equitable adoption, etc., fully open AI systems (i.e., when data, model with weights and architecture, and software are openly licensed(1)) are not always possible or in the best interest of the public good – especially with the advance of highly capable foundation models. Notable risks include the misuse of models by malicious actors without any oversight and control over downstream use and the disablement of model safeguards (2). One example includes the risk of large language models being used to produce mis- and disinformation, potentially undermining democratic institutions and states. However, the idea that highly closed-source foundation models are safer than highly open foundation models is contested among researchers. The complexity of defining ‘openness’ increases with DPGs. According to the DPG Standard, to qualify as a digital public good, solutions must not only meet baseline requirements but also ensure they do no harm by design (3).
In open-source software, the transparency and adaptability assured by open licenses are often seen as inherently “good” since making code available and modifiable drives innovation, trust, and collaboration. This is not always considered to be the case for AI. Exploring this necessitates understanding the current ambiguities surrounding the term “open,” especially in relation to data extractivism, data colonialism, and the economics of open data. This exploration should also consider AI development needs, like computing power and financial access, as well as sensitive data and data privacy concerns.
These challenges call for a nuanced approach to defining the properties that form open-source AI systems, especially concerning these systems as digital public goods. To do so, two outcomes are needed:
- Establishing a framework for a gradient approach to the openness of AI system components, and;
- Outlining the additional guardrails and safety requirements that can help ensure the responsible opening up of AI systems, including documentation requirements and mandatory risk-mitigating practices, which may be included as requirements of the DPG Standard.
These considerations are essential as near-to fully open-sourcing AI systems may increase the ability for community research, auditability, and bringing in diverse perspectives in the development process. Still, they also ultimately limit control over downstream use and risk management.
To solve this issue, the DPGA and UNICEF, in consultation with the CoP, have developed an exploratory framework that introduces a gradient approach to the openness of AI system components. Open-source AI is not a black-and-white debate between closed-source and proprietary or open-source systems. Therefore, this framework attempts to shed light on the greyscale between these two poles and define a necessary and sufficient minimum of openness of AI system components for a product to be considered a digital public good (4).
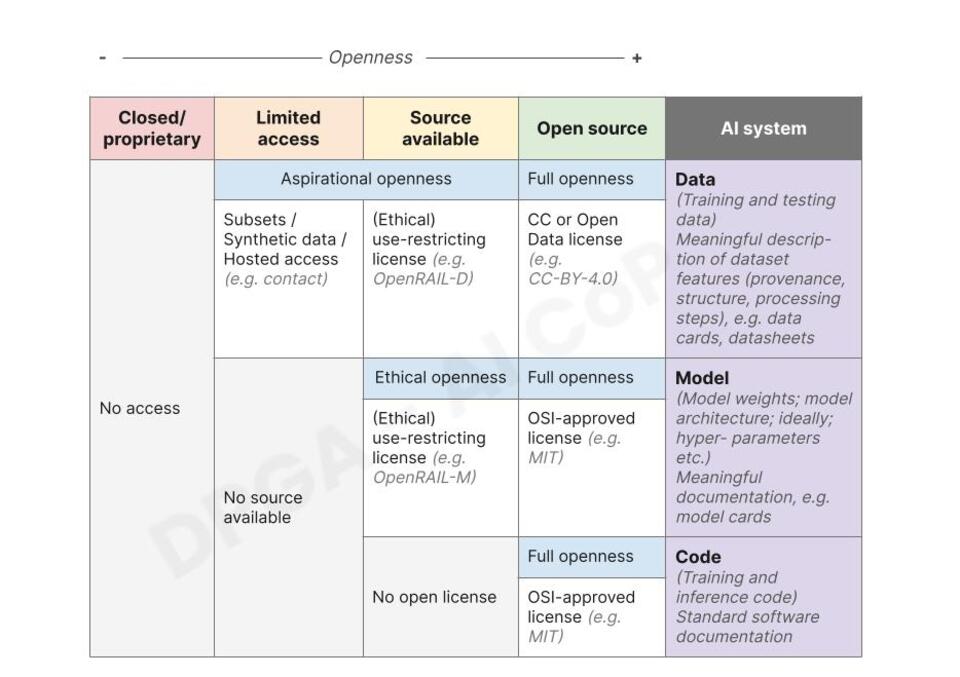
A Gradient Approach to Openness
This framework focuses on the three main components of an AI system, building on the understanding put forward in the CoP’s mid-term discussion paper, including data, model, and code. Among these three components, the openness requirements for AI training data are among the most contested issues in the ongoing discussion on defining open-source AI. The gradient approach framework acknowledges that access to AI training and testing data does not equal access to source code in the open software world – which means that you cannot recreate the model by purely open-sourcing the training data used. There is more to an AI system. But how much do we depend on the original dataset to exercise the right to modify and use a model and to ensure transparency and explainability of the model outcomes? Understanding the underlying training and testing datasets is still essential to understanding, observing, and using the AI model. With that said, the exact reproduction of an AI model is of limited use, given the amount of resources needed to do so.
Reproduction of an AI model does not equal auditing; rather, what is needed to scrutinize a model and, for instance, conduct safety evaluations is access to trained weights and model architecture, not necessarily training data. However, as pointed out above, understanding the training data is still vital – yet, access to the full dataset is not necessarily needed to do so. A gradient approach to AI training data helps to navigate different cultural understandings of open data and address data rights issues, amongst other considerations.
In the CoP, a need to determine what “meaningful openness” constitutes was identified. For example, how do we get to a degree of openness that preserves the attributes like transparency, reusability, and extensibility that are central to open source but does not, strictly speaking, comply with the four freedoms of open source to enable us to navigate the ambiguities previously outlined? In addition, there is a need to help ensure AI DPGs are designed and governed in a way that promotes ethical use and does no harm by design. This could, for instance, include extensive red-teaming, establishing norms and practices for responsible use in a community, publishing a responsible use guide alongside system components (see Meta’s guide for Llama), public reporting requirements in licenses (see the AI2Impact License family for an example) and open-sourcing more artifacts that accelerate AI safety research.
The gradient approach to the openness of AI system components was informed by Irene Solaiman’s work on a gradient release model for generative AI and Tim Berners-Lee’s 5-star deployment model for open data. Both works introduce nuance to their respective fields and reject an all-or-nothing approach. It also builds on the research on the spectrums of openness of text-generating AI models by Andreas Liesenfeld and colleagues.
In this framework, the data component includes training and testing data of an AI model (5). Documentation for this component must include a description of dataset features, including provenance, structure, and processing steps, which need to be captured in a data card or a similar format. The model component includes model weights, hyperparameters, and model architecture. Documentation should come in the form of a model or system card. The code component comprises the training and inference code of the AI system. Standard software documentation would be required as outlined in the DPG Standard. The framework outlines the necessary and sufficient minimum of openness for each of the three components for an AI system to be considered a DPG in its totality.
For the data component, we propose to be the most permissive and define two stages of “aspirational openness” in addition to fully open-source training and testing datasets. Aspirational openness includes:
- Synthetic datasets modeled on the original training and testing data or samples of the datasets used for training or hosted access to the entire training and testing datasets and;
- Datasets with a use-restricting license, such as Open RAIL-D and AI2Impact.
AI training and testing data should be treated as a mandatory dependency instead of a standalone dataset in this framework.
For the model component, we recommend considering either AI models with a full open-source license or models with an (ethical) use-restricting license(6) such as RAIL-M (“ethical openness”). In addition to licensing, we require that a model be made available with its model weights and model architecture in order to be considered a DPG. Ideally, developers should also open-source trained weights, hyperparameters, loss and reward functions, and any other necessary components and knowledge to optimally (cost- and time-efficiently) fine-tune, train, or reproduce a model. This could include training strategies; related models; data processing code; tacit knowledge etc.
We suggest being the least permissive for the code component and requiring training and inference code to be fully open-source according to OSI standards.
With this contribution, we hope to add to the debate on defining open-source AI by bringing in nuance, helping developers to think through the opening process of a system and its components, and inspiring a conversation about the benefits of open-sourcing AI systems. Open-source AI should never be assumed to be an end in itself. Rather, we need to focus on the benefits that come with open-sourcing AI systems. We must carefully approach any definition of AI DPGs not to encourage AI systems’ unsafe and irresponsible release, even if done with the best intentions. In addition, we also acknowledge that additional practices exist that may ensure or come close to realising the benefits of open source in more closed source scenarios, such as AI safety bounties and participatory processes to inform model development, use, and governance (7).
The framework is a starting point for further exploration. Some of the questions the CoP will explore in the coming weeks include reviewing standards for data, model, and system cards; exploring other evolving licenses and requirements in addition to OpenRAIL for inclusion; adding more details on each of the three components’ features to go beyond licensing; considering re-naming the category of “ethical openness”; defining additional guardrails for responsible AI development, which can be integrated into the DPG standard; running case studies to test our approach’s feasibility in vetting DPG applications, and discussing how to prevent product owners from intentionally being more restrictive in opening up data with the introduction of the two aspirational openness categories than is necessary.
We thank all CoP members for their value contributions in developing this framework. As co-hosts of the CoP on AI systems as digital public goods, the DPGA and UNICEF welcome comments on this approach. Please reach out to Lea Gimpel, who leads the DPGA Secretariat’s work on AI if you would like to share your thoughts.
Footnotes
1. With “openly licensed” we refer to licenses that enable users to use, study, share and modify the artifact.
2. For a comprehensive take on the benefits and risks of open-sourcing highly capable models see: Elizabeth Seger et. al. “Open-sourcing highly capable foundation models” (2023)
3. Indicator 9 of the DPG Standard states DPGs must be designed to anticipate, prevent, and do no harm by design.
4. With this, we are also mindful of the ongoing discussion facilitated by OSI to define open-source AI. See the first public draft here.
5. Since the framework is meant to cover the breadth of artificial intelligence techniques, including but not limited to machine-learning and supervised learning, this distinction is used only when applicable.
6. A comprehensive list of which licenses and allowed restrictions will be considered needs to be developed in the CoP as a next step.
7. See Elizabeth Seger et al. “Open-sourcing highly capable foundation models” (2023)